记mariadb导入csv数据错位问题
今早上将xlsx文件导出为csv文件,用sql导入到数据库中间遇到的一点问题。
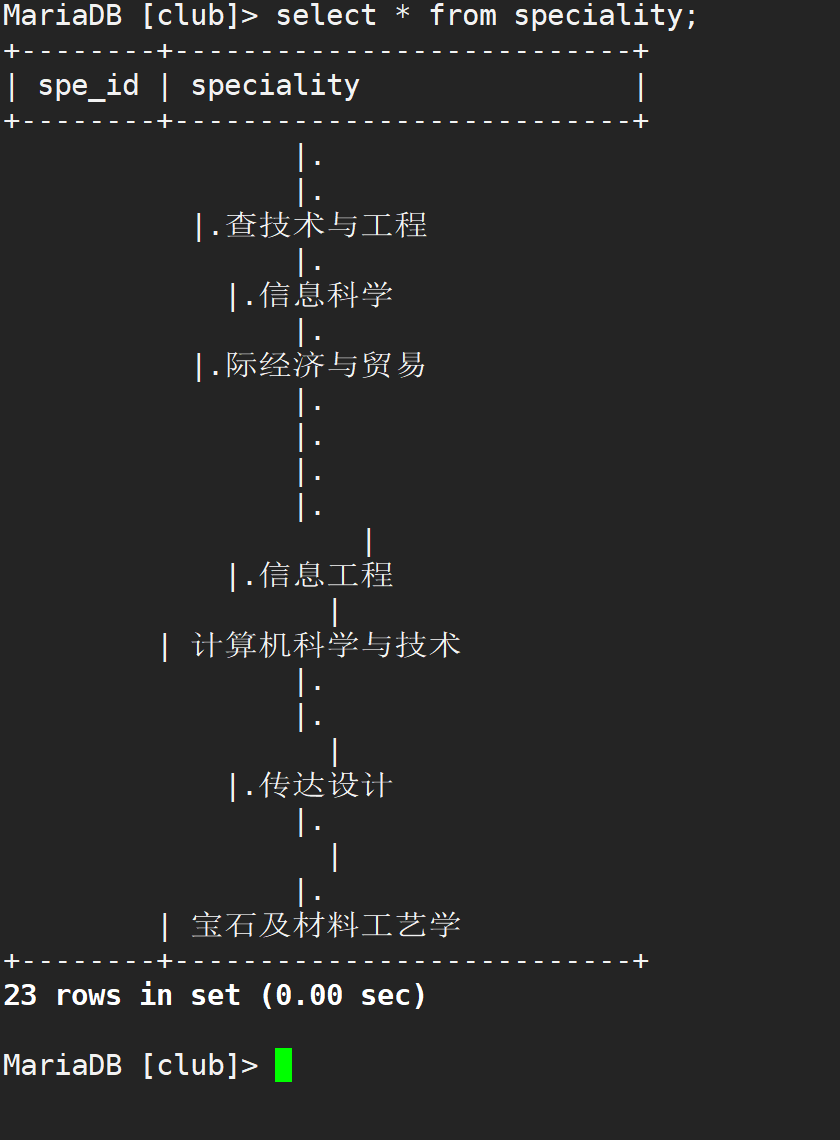 ▲ 结果如图
▲ 结果如图
从这错乱可以直观的看出(打印内容过多也可能错乱),应该是哪里出问题了。表是自己设计的,可以排除不是编码和字段长度不够引起的。
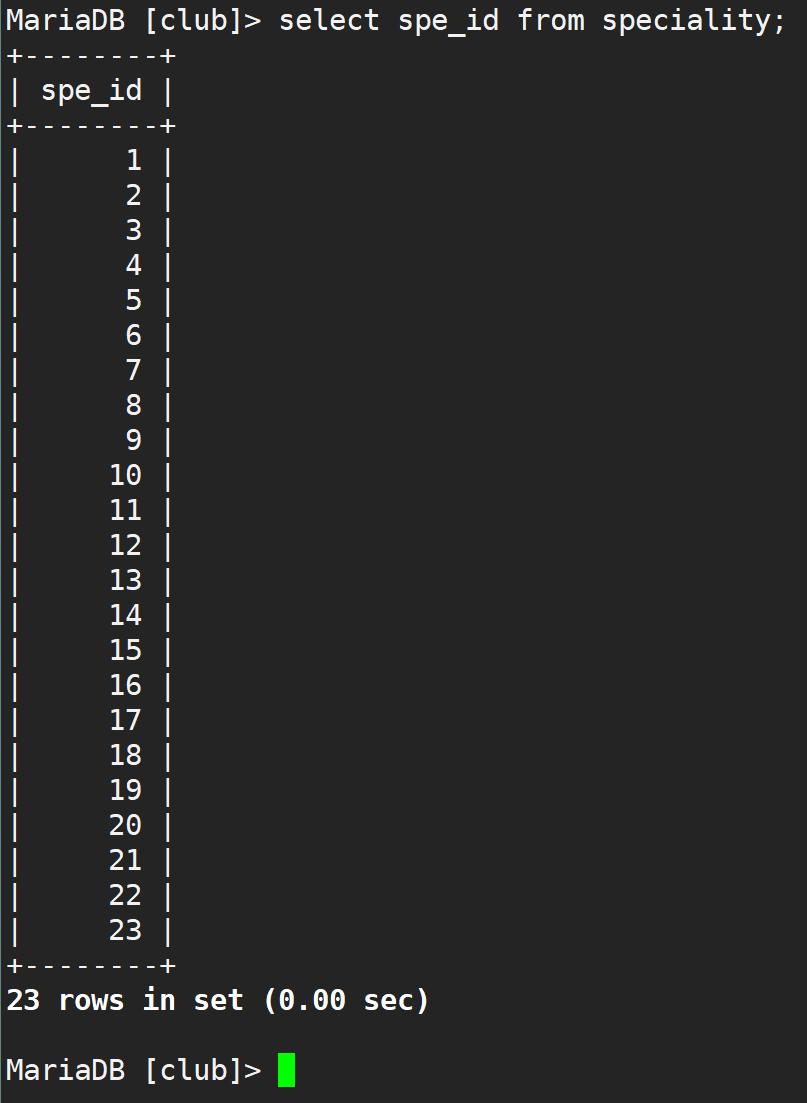 ▲ 查看id字段
▲ 查看id字段
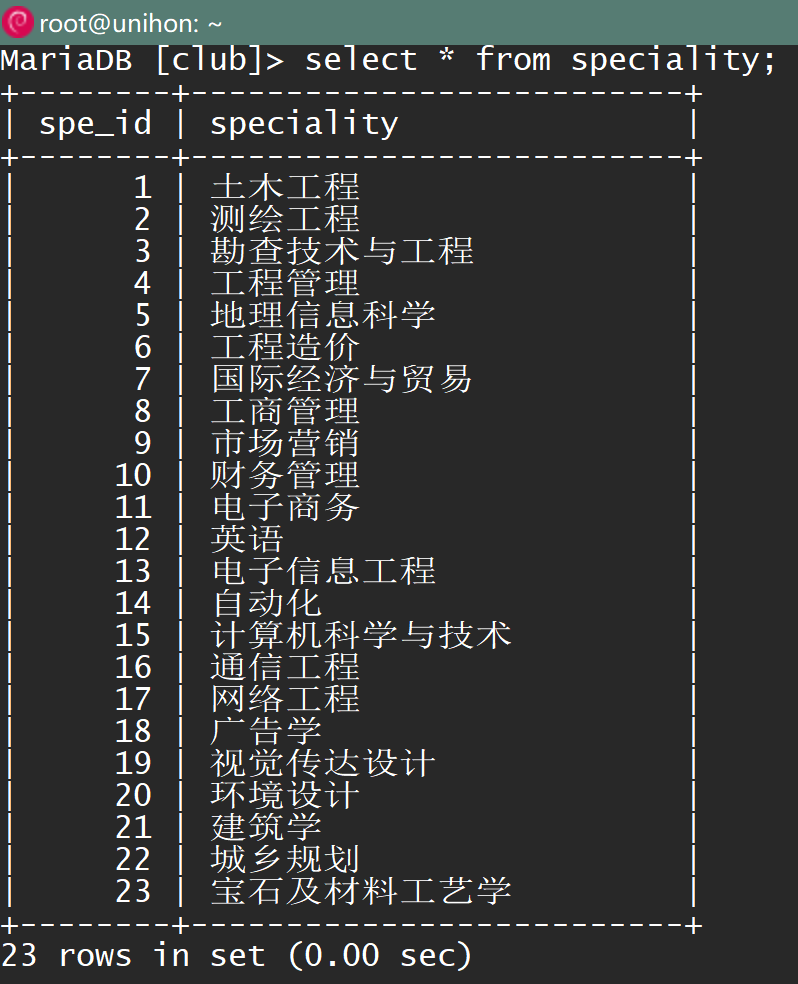
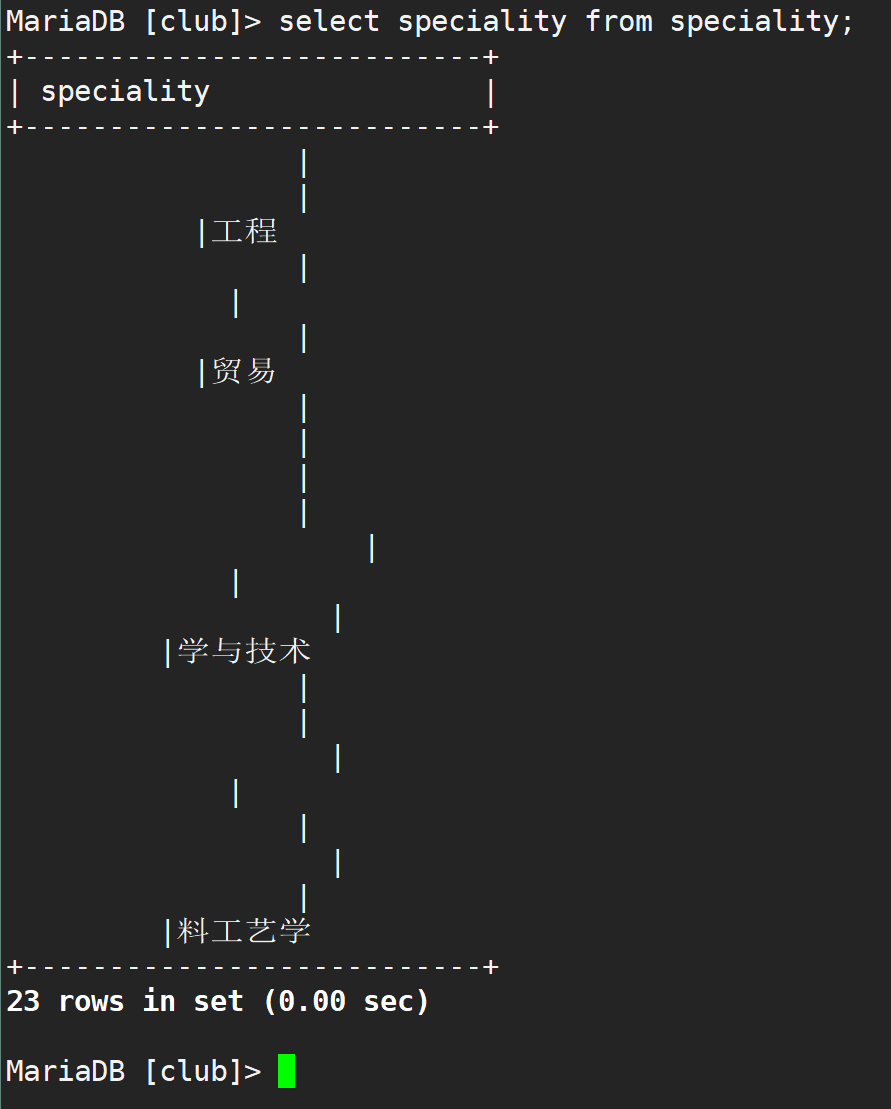 ▲ 查看speciality字段
▲ 查看speciality字段
从结果可以看出,问题应该在speciality字段上面。后面我接着重新导了一份csv数据,结果一样。着实是想不到问题出在哪里。疑问为什么id好好的,有中文那个字段就乱七八糟了,不应该是编码问题啊?接着尝试性的将表备份出来,看下。
 ▲ 查看备份数据
▲ 查看备份数据
这下清楚了,每行数据后面多了\r,这个应该是windows下面的换行符。知道问题之后,就好解决了。
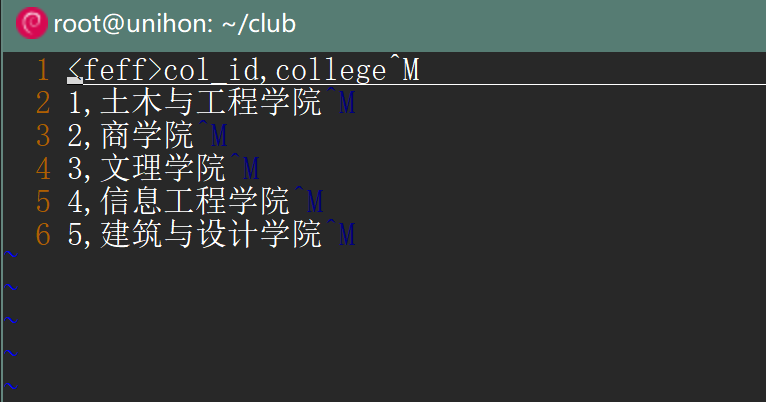 ▲ 以二进制方式打开csv文件
▲ 以二进制方式打开csv文件
可以看到^M结尾的换行符,这个就是要找要的\r,全部删除掉就好了,至于文件开头的<feff>说是utf-8标识相关的,先不理。
vim下面有两个方法(可能还有其他的)批量把\r给删除掉,用的都是替换:
1 | :%s/\r//g |
如果是对文件进行批量处理,可以将文件集中到一个目录下,接着用下面的命令:
1 | ls|xargs sed -i 's/\r//g' |
 ▲ 删除
▲ 删除\r换行符后,重新导入
解决。
- Blog Link: https://unihon.github.io/2018-10/db-value-question/
- Copyright Declaration: The author owns the copyright. Please indicate the source reproduced!